Talking about Europe: Die Zeit and Der Spiegel 1940s-2010s
An on-going research project is seeking to quantify and analyse printed media discourses about Europe over the decades since the end of the Second World War. A first snapshot screened more than 2.8 million articles in Le Monde between 1944 and 2018. In this second instalment we carry out an analogous exercise on a dataset of more the 500 thousand articles from two German weekly magazines: Die Zeit and Der Spiegel. We also report on the on-going work to refine the quantitative methodology.
Introduction
Our ongoing research focuses on how, over the decades since the end of the Second World War, media coverage of European issues has changed, arguably corresponding to the changing interest of their readership. The research is progressing in steps; a more advanced analysis, could also give indications about divergence or convergence patterns between national media.
Printed press is the only possible source of data for the long period to be covered by the analysis, so only newspaper and magazine articles are considered as a proxy for measuring the level of European public debate. The desire to cover a very long period of time also dictates the choice to target the analysis only at the six founding members of the EU. Furthermore, in order to limit the heavy data-collection burden, the analysis concentrates – for the time being – on the three largest founding members: Germany, France and Italy.
Results
More in the hope of provoking a discussion than of providing conclusive results, we presented in a previous post preliminary estimates of the ratio of “European” news versus the total number of news pieces (E/T) for the French newspaper Le Monde between 1944 and 2018 (https://bruegel.org/2019/03/talking-about-europe-le-monde-1944-2018/). In this post we carry out a similar exercise for two German weekly magazines, Die Zeit and Der Spiegel.
The methodology has evolved with respect to the one used for Le Mondeand thus the results are not directly comparable. The on going effort aims at reducing the occurrences in which an article could be qualified as European, just because a “European” term is included, even if the subject matter is not European at all1 (in statistics parlance this would be a type 1 error, concluding that the hypothesis is right while it is in reality wrong) or, vice versa, not including an article that indeed talks about Europe (this would be a type 2 error). Basically the issue is to find a good balance between the two kinds of errors. The method used in this post to establish this balance is explained in the second section, but work is on-going to further improve it.
There are thus important caveats to be taken into account in looking at the results reported in Figure 1 with the frequency of European news to total news, what was called above E/T, in the two weekly magazines. Basically the most solid message is the behaviour over time of the two lines, not their level.
Figure 1: Ratio of European news to total news (E/T) in Der Spiegel archive (1947-2016) and in Die Zeit archive (1946-2016)
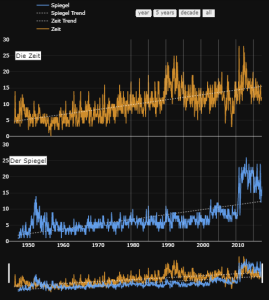
While a full comparison between the results obtained from looking at different newspapers will be carried out in subsequent pieces reporting on our on-going research, with improved methodology, an obvious and important remark is that, as observed for Le Monde, also in the German magazines there is a strong positive trend of the E/T ratio: this starts in the second half of the 1940s just below 5 per cent for Die Zeit and at around 2 per cent for Der Spiegel, while reaching in both magazines around 12-15 per cent per cent since the beginning of the 2010s.
Three additional phenomena stand out from a visual inspection of the figures.
First, one noteworthy increase in the E/T ratio is visible in both magazines at the turn between 2009 and 2010, when the financial crisis transformed itself into a European sovereign crisis, following the revelation of a much higher than communicated fiscal deficit in Greece.
Second, the dates of some important events, where we could have expected an increase of the ratio, show instead only a relatively modest reaction. This includes, for instance, the Hague summit of heads of governments that took place in 1969, and the European Monetary System in 1978. European elections, indicated by the white vertical bars, instead highlight the expected spikes, which appear more clearly in Die Zeit than for Der Spiegel.
Finally, there are some examples of significant differences of reaction between the two weeklies with respect to the same events. One case stands out: the EMS crisis originated by the Danish and French referendums on the Maastricht Treaty in 1992 is very visible in an increase in the E/T ratio for Die Zeit, but not for Der Spiegel.
Methodology
The analysis of the two selected newsgroups is still at an early, exploratory stage. We constructed a set of keywords (see below) that can be a proxy for the concept of “European news”. Before moving to topic modelling approaches, we decided to explore the corpus by constructing a score based on the number of matches of keywords in the articles’ body. In the post published with the results from Le Monde, any article containing one of the keywords was considered as European. This is clearly an upward biased estimate of the E variable: including one of the European keywords is a necessary but not a sufficient condition to qualify an article as European. Some method is needed to avoid a large number of Type 1 errors. In estimating E/T in this post on the German weeklies, to deflate the importance of common words such as “euro” or “europäisch” (and its various cases), we weigh the score of these two terms at only 0.5. The articles forming our “E” variable, are then those that score more than 3 points, given our set of keywords.
This procedure was run on a dataset of 310 thousand and 220 thousand articles for Spiegel and Zeit, respectively. The matched articles are almost 24 thousand for Die Zeit, and 22 thousand in Der Spiegel.
Clearly this methodology represents only a preliminary attempt to classify and recognize “European” news, and suffer from a number of drawbacks. First, the analysis was run on the raw data, which has not been pre-processed via the typical text-mining techniques (stop-words removal, stemming, and lemmatization). Sections that might be a source of noise, as for Le Monde, were not recognized and excluded from our measure of “E” (e.g. sport),
In general, the keyword-scoring methodology helps us quickly and simply explore what is the intensity of these keywords across a very long time span, but it’s far from ideal, as the probability of an article belonging to a topic is not being modelled in a sophisticated way. In further steps of the project we will implement and test, following a more scientific approach, different topic modelling techniques.
This post was prepared with the assistance of Enrico Bergamini, Emmanuel Mourlon-Druol, and Giuseppe Porcaro
- An example may illustrate the problem: in an article published in Der Spiegel in April 1960 (Der Riese räkelt sich – The giant lolls) about the then President of Brasil, Juscelino Kubitschek, and the new capital of Brasil, Brasilia, one can read the sentence: “Etwa 60 Prozent der brasilianischen Bevölkerung sind europäischer Abstammung”, i.e. circa 60 per cent of the Brazilian population is of European origin. Here the adjective European does not indicate that the subject of the article is Europe. The problem is of course more acute after the introduction of the euro, where the term euro can just indicate the measurement unit of value as in: The car costs 20.000 euro.[↩]
